About TheLMA
The TheLMA project aims at providing a comprehensive framework for implementing lattice Boltzmann method (LBM) flow solvers on graphics processing units (GPUs) and hybrid clusters. Development is based on Nvidia CUDA, which in our opinion is the most mature technology up to now for general purpose computations on GPUs. As outlined in Fig. 1, the framework consists in a set of modules designed such as to improve code reusability.
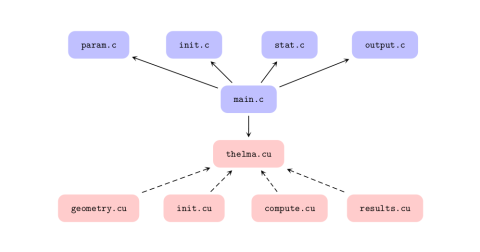
The compute.cu module contains the collision and propagation kernel. Several versions are already implemented, including an isothermal multiple-relaxation-time D3Q19, a hybrid D3Q19 with finite-difference thermal component, and an isothermal D3Q19 with Smagorinsky subgrid-scale model. Complex geometries may be represented accurately using bit-fields and linearly interpolated bounce-back boundary conditions. Moreover, the framework includes native multi-GPU support based on POSIX threads, which allow the solvers to run on up to eight computing devices in parallel. Extension of TheLMA to hybrid clusters using the MPI library is ongoing work.
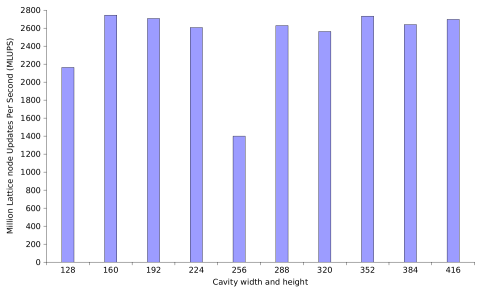
for the flow past a sphere in a square channel of length 1024
Performance using a Tyan B7015 server with eight Nvidia Tesla C1060 computing devices ranges up to 2744 million lattice node updates per second (MLUPS) for isothermal single precision solvers and to 1920 MLUPS for thermal single precision solvers. Recent studies (Lee et al., ISCA'10) have shown that optimised multi-threaded single precision CPU implementations of isothermal LBM solvers running on up-to-date hardware achieve at most 85 MLUPS, which is 32× less than our maximum performance.